
Google's Gemini 3.1 Flash-Lite is faster and smarter, but costs nearly four times more to run
Google launched Gemini 3.1 Flash-Lite on March 3, 2026, billing it as its "most cost-effective" model yet. The model delivers real improvements in speed and reasoning — but developers who chose earlier Flash-Lite versions for their rock-bottom pricing will find the economics have shifted sharply. Output prices have risen 3.75x compared to Gemini 2.5 Flash-Lite, marking a clear departure from what was once the budget floor of Google's AI model lineup.
What Happened
Google released Gemini 3.1 Flash-Lite on March 3, 2026 as a preview model, available on Google AI Studio and Vertex AI. The model is positioned as the fastest and most cost-efficient option in Google's Gemini 3 series.
The capability improvements are real. Gemini 3.1 Flash-Lite processes 363 tokens per second — 45% faster than Gemini 2.5 Flash's 249 tokens per second, according to benchmark data reported by Officechai. On GPQA Diamond, a test of graduate-level scientific reasoning, the model scores 86.9%. It scores 76.8% on MMMU-Pro, which tests reasoning across text, images, and scientific content. A new "adjustable thinking" feature lets developers control how much reasoning the model applies to any given task, offering a lever to trade performance for cost.
The pricing tells a different story. According to the official Google AI developer pricing page, input costs rose from $0.10 to $0.25 per million tokens — a 2.5x increase — while output costs jumped from $0.40 to $1.50 per million tokens, a 3.75x increase. Both figures compare to Gemini 2.0 and 2.5 Flash-Lite, the two prior generations that had maintained the same price point, as confirmed by The-Decoder.
Why It Matters
Flash-Lite was Google's answer to developers running AI workloads at scale on tight budgets. Launched with Gemini 2.0, it held a stable price of $0.10 input and $0.40 output per million tokens — a baseline that made it attractive for cost-sensitive applications like real-time translation, content classification, and high-volume document processing. With Gemini 3.1, that baseline is gone.
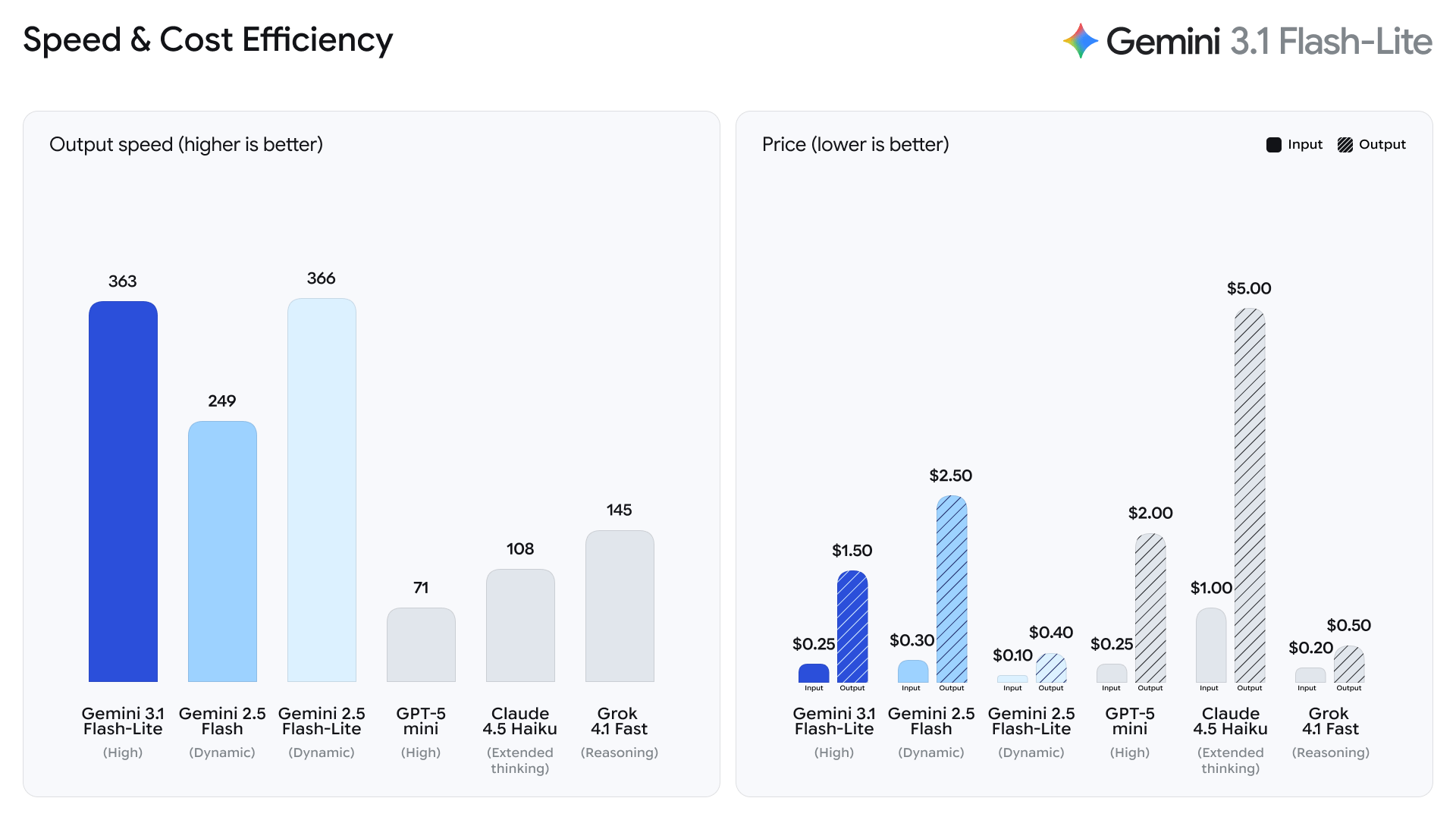
Google's marketing frames the value proposition differently. The company's official blog calls it "our most cost-effective AI model yet" — a claim supported by comparing Flash-Lite's $0.25/$1.50 pricing to the full Gemini 2.5 Flash tier at $0.30 input and $2.50 output per million tokens. By that comparison, the numbers hold. But the relevant comparison for existing Flash-Lite users is not against a more expensive tier — it is against the previous Flash-Lite generation they built their workflows around.
There is also a question about whether Flash-Lite still occupies a defensible position within Google's own catalog. Independent AI analyst Adam Holter writes that Gemini 3 Flash without reasoning is reportedly both cheaper and more capable than the new Flash-Lite: "Gemini 3 Flash without reasoning is both cheaper and more intelligent, meaning Flash-Lite is not on the Pareto frontier when you plot cost against intelligence — there is a strictly better option available at a lower price with higher capability." If accurate, Flash-Lite's value case narrows to its speed advantage — 363 tokens per second is genuinely fast — and its multimodal breadth across text, images, audio, and video.
The generational pattern is worth noting. As Holter observes, "Google also raised the price compared to prior Flash-Lite models. Their pricing hit a low point with Gemini 2, and the current Flash-Lite costs more than three times the Gemini 2.0 Flash model." Gemini 3.1 Flash-Lite is still a preview release, meaning pricing could adjust before general availability. But each Flash-Lite generation since Gemini 2.0 has cost more than the last, and the gap is widening.
Sources
- T2The-Decodernews
- T2Google Blognews
- T2
- T2Adam Holternews
- T2Officechainews
Stay informed. The best AI coverage, delivered weekly.